H2O EvalGPT 是 H2O.ai 用于评估和比较 LLM 大模型的开放工具,它提供了一个平台来了解模型在大量任务和基准测试中的性能。无论你是想使用大模型自动化工作流程或任务,H2O EvalGPT 都可以提供流行、开源、高性能大模型的详细排行榜,帮助你为项目选择最有效的模型完成具体任务。

H2O EvalGPT 的主要特点
-
相关性:H2O EvalGPT 根据行业特定数据评估流行的大语言模型,从而了解其在实际场景中的表现。
-
透明度: H2O EvalGPT 通过开放的排行榜显示顶级模型评级和详细的评估指标,确保完全可重复性。
-
速度和更新:全自动和响应式平台每周更新排行榜,显着减少评估模型提交所需的时间。
-
范围:评估各种任务的模型,并随着时间的推移添加新的指标和基准,以全面了解模型的功能。
-
交互性和人工一致性:H2O EvalGPT 提供手动运行 A/B 测试的能力,提供对模型评估的进一步见解,并确保自动评估和人工评估之间的一致性。
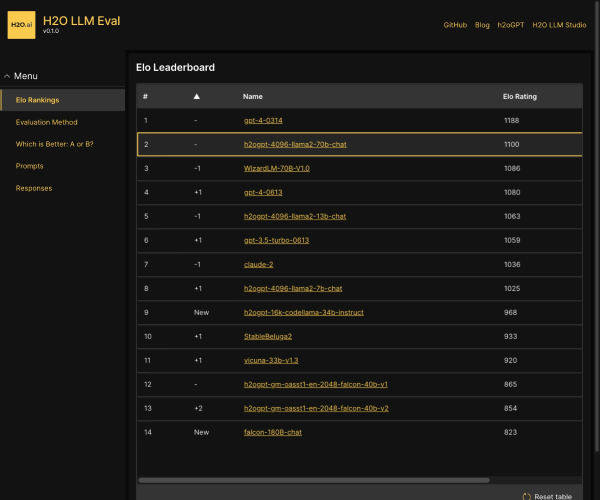
这排行榜直观,选模型省事。
界面暗色系太刺眼了。
速度快,周更挺给力。
我之前也试过类似工具,感觉还行。
这个Elo分数看着有点玄乎。
想问下,排行榜会不会漏掉小模型?
界面左侧导航有点挤,点不清。
我觉得交互性的A/B测试挺有价值,只是操作流程稍显繁琐。
用了几次评估,模型排序挺靠谱,但有时候分数波动大,想知道背后算法细节。
我最近在项目里挑模型,看到这个平台真是省了不少时间,尤其是每周自动更新的排行榜,让我能快速对比新模型,感觉以后选模型会更轻松。