大规模多任务语言理解基准
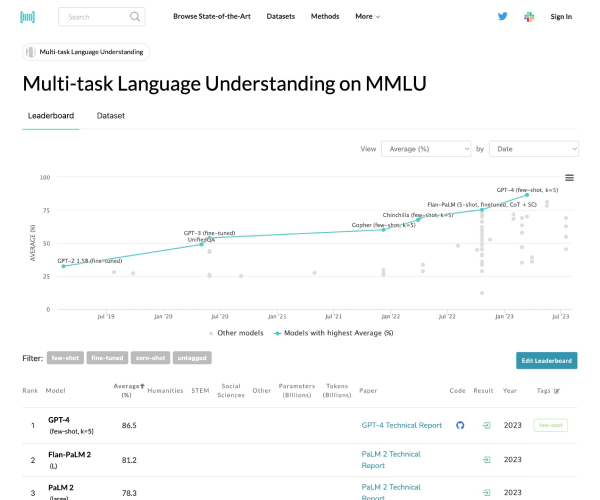
MMLU 全称 Massive Multitask Language Understanding,是一种针对大模型的语言理解能力的测评,是目前最著名的大模型语义理解测评之一,由UC Berkeley大学的研究人员在2020年9月推出。该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。
测评题目太杂,刷到数学都头大。
这套题库感觉挺吓人,尤其法律那块。
界面配色有点刺眼,眼睛受不了 😫
功能倒是全,速度慢得像龟速。
我刚用了大模型,结果分数意外低。
建议加点中文任务,太偏英文。
这测评到底想干嘛?感觉像秀技术。
我觉得题目选取有点偏科,数学和历史占比太高,想要更均衡点。
界面按钮排布有点乱,用起来总找不到对的入口,体验感一般,建议重新布局,真的挺烦。
我之前也用过类似测评,结果总是被数学卡住,后来换了别的模型才稍微好一点,真是太挑剔了。
测评题目太杂,刷到数学都头大。
这套题库感觉挺吓人,尤其法律那块。
界面配色有点刺眼,眼睛受不了 😫
功能倒是全,速度慢得像龟速。
我刚用了大模型,结果分数意外低。
建议加点中文任务,太偏英文。
这测评到底想干嘛?感觉像秀技术。
我觉得题目选取有点偏科,数学和历史占比太高,想要更均衡点。
界面按钮排布有点乱,用起来总找不到对的入口,体验感一般,建议重新布局,真的挺烦。
我之前也用过类似测评,结果总是被数学卡住,后来换了别的模型才稍微好一点,真是太挑剔了。