Quest AI
AI将设计稿生成React代码,支持JavaScript和TypeScript
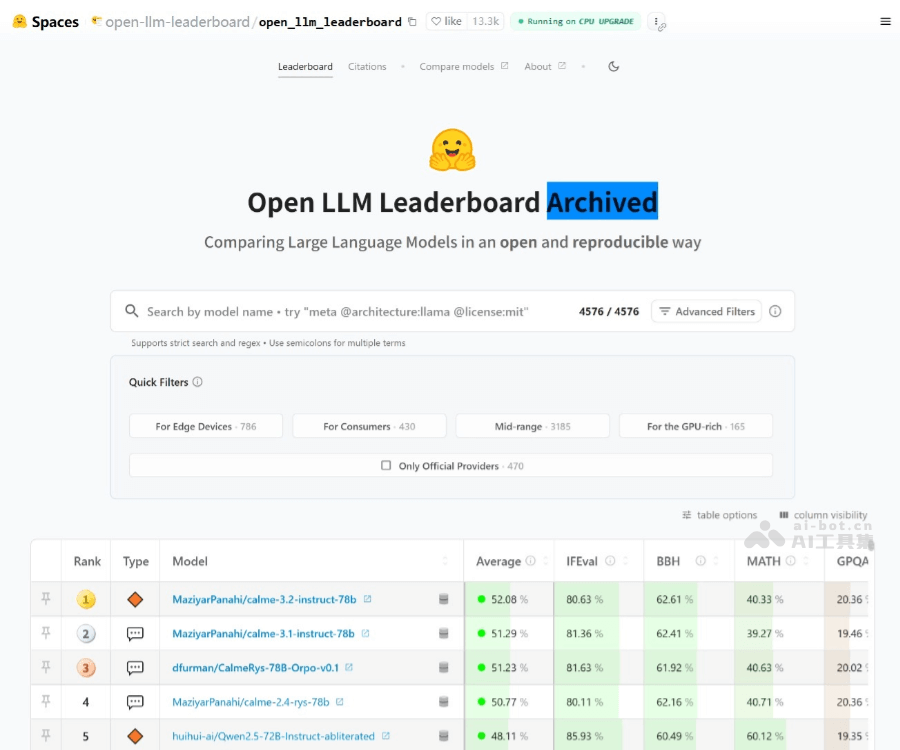
Open LLM Leaderboard 是最大的大模型和数据集社区 HuggingFace 推出的开源大模型排行榜单,基于 Eleuther AI Language Model Evaluation Harness(Eleuther AI语言模型评估框架)封装。Open LLM Leaderboard通过多种基准测试(如 IFEval、BBH、MATH 等),从指令遵循、复杂推理、数学解题、专业知识问答等多个维度对模型进行评估。排行榜涵盖预训练模型、聊天模型等多种类型,提供详细的数值结果和模型输入输出细节。Open LLM Leaderboard 能帮助用户筛选出当前最先进的模型,推动开源社区的进步。

git clone git@github.com:huggingface/lm-evaluation-harness.git
cd lm-evaluation-harness
git checkout main
pip install -e .
lm-eval --model_args="pretrained=<your_model>,revision=<your_model_revision>,dtype=<model_dtype>" --tasks=leaderboard --batch_size=auto --output_path=<output_path><your_model>、<your_model_revision> 和 <output_path> 为实际值。--apply_chat_template 和 --fewshot_as_multiturn 选项。
筛模型确实快,不过有些冷门模型没标训练数据,有点懵。
页面加载慢就算了,筛选还动不动失灵,急死人。
小众模型冒头真好,总算不用只看那几个大厂脸了。