OpenCompass是什么
OpenCompass是上海人工智能实验室(上海AI实验室)于2023年8月正式推出的大模型开放评测体系,通过完整开源可复现的评测框架,支持大语言模型、多模态模型各类模型的一站式评测,并定期公布评测结果榜单。OpenCompass包含 CompassKit(评估工具包)、CompassHub(基准社区)和 CompassRank(评估排行榜)三大核心部分。OpenCompass支持多种模型(如 Hugging Face 模型、API 模型等),涵盖语言、知识、推理等八大能力维度,提供零样本、少样本等多种评估方法。OpenCompass具备分布式高效评估、灵活扩展等特点,已吸引众多知名企业和高校合作,致力于推动大模型评估的标准化和规范化发展。

OpenCompass的主要功能
-
模型评估工具(CompassKit):提供丰富的评估基准和模型模板,支持零样本、少样本等多种评估方式,方便用户根据需求灵活扩展。
-
基准社区(CompassHub):支持用户发布和共享评估基准,社区内可展示排行榜,高质量基准可被纳入官方排行榜。
-
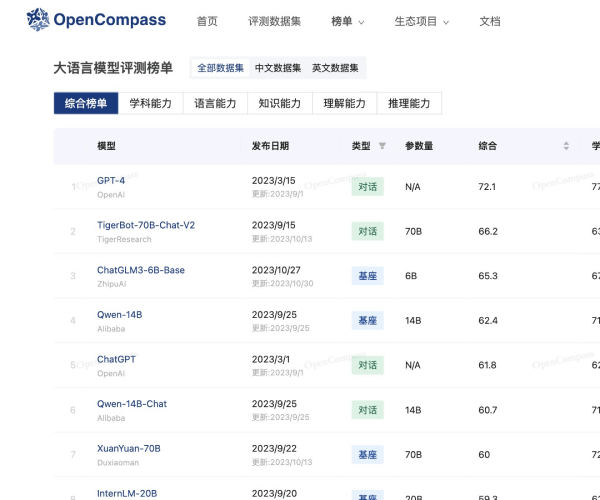
评估排行榜(CompassRank):提供全面、客观的评分和排名,涵盖八大能力维度,支持语言模型和多模态模型评估,已有众多模型参与。
-
高效评估系统:支持分布式评估,快速处理大规模模型,配备实验管理和报告工具,方便实时查看结果。
如何使用OpenCompass
-
访问官网:访问 OpenCompass 官网,了解平台功能和资源。
-
选择功能模块:根据需求选择 CompassKit(评估工具)、CompassHub(基准社区)或 CompassRank(排行榜)。
-
提交模型或基准:在 CompassRank 提交模型的 API 或仓库地址,或在 CompassHub 发布评估基准。
-
安装与配置:如果使用 CompassKit,从 GitHub 克隆代码,安装依赖并配置环境。
-
执行评估:使用 CompassKit 进行本地评估,或等待官方评估结果更新至 CompassRank。
-
查看结果:在 CompassRank 查看模型排名,或用 CompassKit 查看本地评估报告。
OpenCompass的应用场景
-
模型性能评估与优化:企业和研究机构对语言模型或多模态模型进行多维度评估,精准定位模型优势与不足,进而优化模型性能。
-
学术研究:研究人员借助其丰富基准开展模型对比研究,推动学术发展。
-
企业级应用开发:企业在开发智能客服、智能写作等应用时,评估不同模型在特定任务上的表现,选择或定制最适合的模型。
-
教育与培训:教育机构将 OpenCompass 作为教学工具,帮助学生学习大模型的评估方法和优化技巧,提升对人工智能技术的理解和应用能力。
-
社区共建与共享:开发者和研究者将模型或基准贡献至 OpenCompass 社区,与其他用户共享资源,共同推动大模型评估技术的发展。




和论文里自己写的评测脚本比,优势在哪?
感觉是给“炼丹师”们准备的利器。
希望文档能多加点图,纯文字看着累。
能不能评估模型在特定领域(比如医疗、法律)的表现?
对于模型部署后的线上效果,有评估方法吗?
看起来是纯命令行工具?有图形界面吗?
这么多模型和基准,管理起来方便吗?
会不会很吃硬件资源?
对于刚入门的小白,从哪部分开始学比较好?
希望社区氛围能活跃一点,多些干货分享。